Handling null bytes in JSON payloads with postgres
Leo Sjöberg • June 28, 2024
- A null byte is a byte representing nothingness. If you're inserting a null byte in code, you'll likely write
\u0000, or\x00; these are escape sequences. - In UTF-8, the null byte is represented by the codepoint
0. A codepoint is just a numeric value that designates a UTF-8 character. - An escape sequence represents UTF-8 codepoints in a more limited character set, such as ASCII. This means you can write invisible characters, like a null byte, as
\u0000in your IDE and have that compile to an actual null byte.
As The Chainsmokers' "Don't Let Me" (which is my pager sound) wakes me up at 01:24 AM, I read the alert
for INC-5607: parsing JSON into payload: invalid character '|' in string escape code. I spend 25
minutes investigating with little progress until, after escalating to a coworker to confirm, we agree
that it can wait until the morning. I share some notes from my initial observations in the incident
channel in Slack, and head back to bed for a few hours of sleep.
The next morning, after another hour of digging, I share an incident update:
We're not sure why this is happening yet, but suspect it may be caused by recent changes to our handling of null bytes resulting in invalid JSON.
Having dug into some of the code, we're gonna investigate whether a change last week to strip null-bytes caused this problem.
It's possible we're either doing something wrong in how we strip null bytes (which we do because they can't be inserted into postgres), and end up stripping too much, or that it's somehow possible to end up with "load-bearing" null data (i.e as some weird json delimiter).
I didn't know it yet, but this was the beginning of a deep dive into JSON, UTF-8, and the Go encoding library.
Some background
Before we dig into what happened, let's talk about JSON, postgres, and null bytes.
Firstly, the JSON payload itself. Null bytes are not valid in JSON payloads according to
the spec.
However, any UTF-8 escape sequences are! This means you can represent a null byte as \u0000, the
literal byte sequence ['\\', 'u', '0', '0', '0', '0'].
When a JSON payload is processed through a decoder, it will parse the escape sequence and convert it to the actual null byte.
So what about postgres? Postgres has two ways to store JSON data: json and jsonb. When you use a
jsonb column, postgres will decompose the JSON and store it in a binary format in a TEXT field under
the hood. This means postgres ends up parsing the JSON, and then attempting to store it. When you use
a json column, postgres will store the JSON as a raw string (also in TEXT), and not attempt to parse it at insert-time,
but rather at query-time. This means you can insert invalid JSON into a json column, but you'll only
find out when you try to query it.
However, postgres has one little caveat: it doesn't support storing null bytes in the TEXT data type!
This means that if you try to insert a JSON payload with a null byte escape sequence into a jsonb
column, postgres will parse the escape sequence as a null byte, and then fail to store it. When this
happens, you'll get the error code Unsupported Unicode escape sequence (SQLSTATE 22P05). But that's
not the error we were seeing; we were seeing invalid character '|' in string escape code, coming
from our Go code 🤔
jsonb instead of json?
jsonb makes querying JSON columns much more efficient when you use the JSON functions, i.e foo->>bar,
since the data is already stored in a decomposed binary format. When using a json column, postgres
has to parse the JSON at query-time.
It also means you'll end up getting the same error, but later, when using a json field.
Discovering the what
This was all coming from us ingesting a webhook, so I took the failing payload from production and attempted to reproduce with it in my local environment. Lo' and behold, I thought I had figured out what went wrong:
We've discovered the cause of this, and verified it is indeed caused by how we sanitise the input data.
As far as I can tell, Sentry did send us valid JSON. We, somehow, then parsed that JSON incorrectly, such that
\\u0000(an escaped null byte, which should be parsed as['\', 'u', '0', '0', '0', '0']) got parsed as a backslash and a null byte (['\', '\u0000']).When we then strip null-bytes, we can end up with invalid escape sequences, in this case trying to parse
\|.I'm now going to look into how we ended up parsing this as a null byte in the first place, as I don't think that should've happened.
Okay, so, I wasn't entirely correct here, but I had a local reproduction, and a suspicion. At this point, it's 4 PM the next day. Because of some meeting breaks, total time spent up until this point was around three hours of investigation, and still not finding a cause... and then the penny dropped
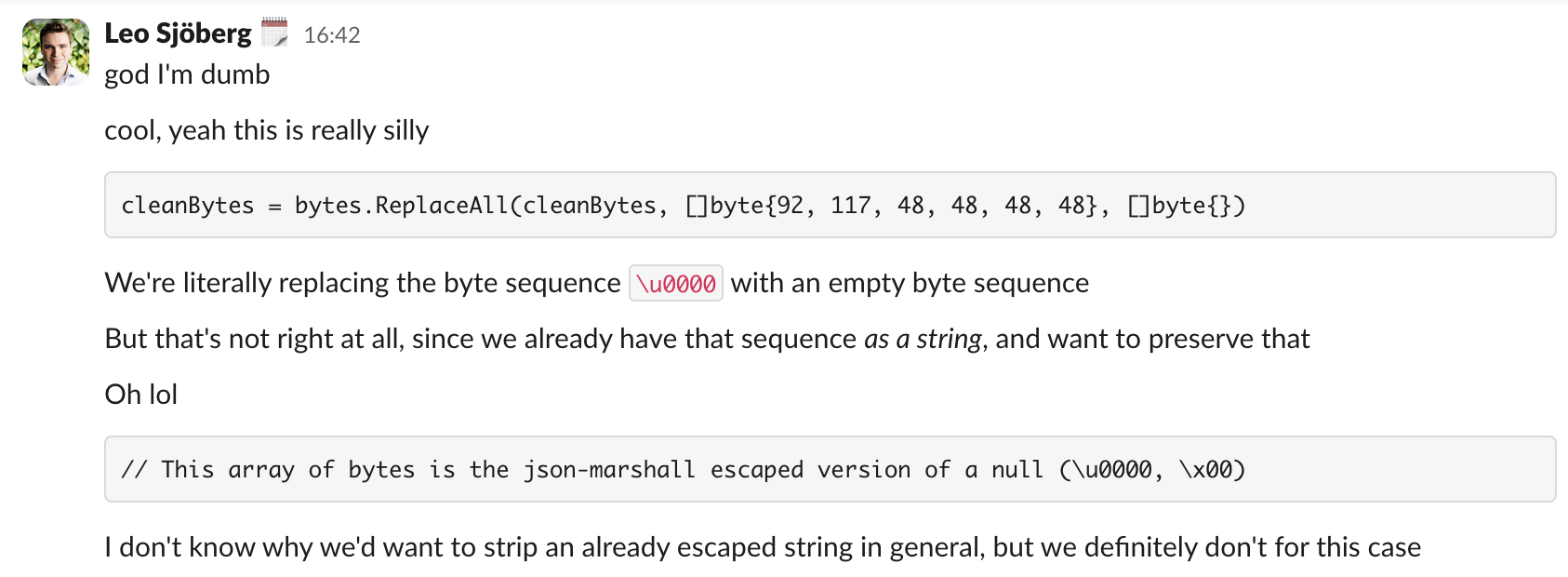
Three hours in, and I've realised that we strip the byte sequence \u0000, which works fine if your payload
actually contains a null byte, but not if it's an escaped null byte.
For the sequence \\u0000|, it means we strip out the middle bit, and end up with \|, which Go's
JSON library then can't parse because it's invalid (and it'd fail inserting into postgres if our code
ever got that far). But why did we strip out this byte sequence?
3 days earlier: INC-5579
A few days before my incident, we had another incident caused by null bytes. In that incident, we received
actual null bytes (\u0000) in the JSON payload from Sentry, rather than escaped null bytes (\\u0000).
So to fix that, we introduced a change to strip out that byte sequence, which worked until we received an
escaped null byte!
That code looked like this:
1func SanitizeByteArray(byteArray []byte) []byte {2 cleanBytes := bytes.ToValidUTF8(byteArray, []byte{})3 // This array of bytes is the json-marshall escaped version of a null (\u0000, \x00)4 cleanBytes = bytes.ReplaceAll(cleanBytes, []byte{92, 117, 48, 48, 48, 48}, []byte{})5 // And also strip generic null character just in-case6 cleanBytes = bytes.Trim(cleanBytes, "\x00")7 return cleanBytes8}This takes care of any payload that just contains null bytes, like this:
1{"error": "something went \u0000wrong"}2// -->3{"error": "something went wrong"}This allowed us to close out that incident, but it caused us to create invalid JSON if the input was escaped:
1{"error": "something went \\u0000wrong"}2// -->3{"error": "something went \wrong"}Since we naively stripped bytes, we ended up creating invalid payloads from valid ones (in the example
above, \w gets parsed as an escape sequence, which is invalid).
Why it's not enough to just strip the actual null byte
In the code above, you may have noticed the following line:
1cleanBytes = bytes.Trim(cleanBytes, "\x00")If you're like me when I first looked at this, you may think "wait, isn't it enough to just have that code?"; after all, Go always operates in UTF8, so you may expect, as I initially did, that escape sequences would be parsed.
However, in this case, we're dealing with raw input data over-the-wire, and Go will simply parse this as
a UTF-8 6-character sequence []byte{'\\', 'u', '0', '0', '0', '0'} instead of running any encoding.
Coming up with options
At this point, we knew what was happening, why the change was introduced, and I started doing some research into what options we'd have. I spent the rest of the day combining research with various experiments as I kept learning.
Option 1: decoding and re-encoding
My first attempt was to try and coerce the input data into something with real null bytes, so I could strip null bytes. Having tried a bunch of different encodings, I slowly came to accept I'd have to do what I really didn't want to do: run the entire input through a JSON decoder, strip null bytes after decoding, and then re-encode it to an output stream.
At this point, I'd spent the entire afternoon talking to myself in a Slack channel
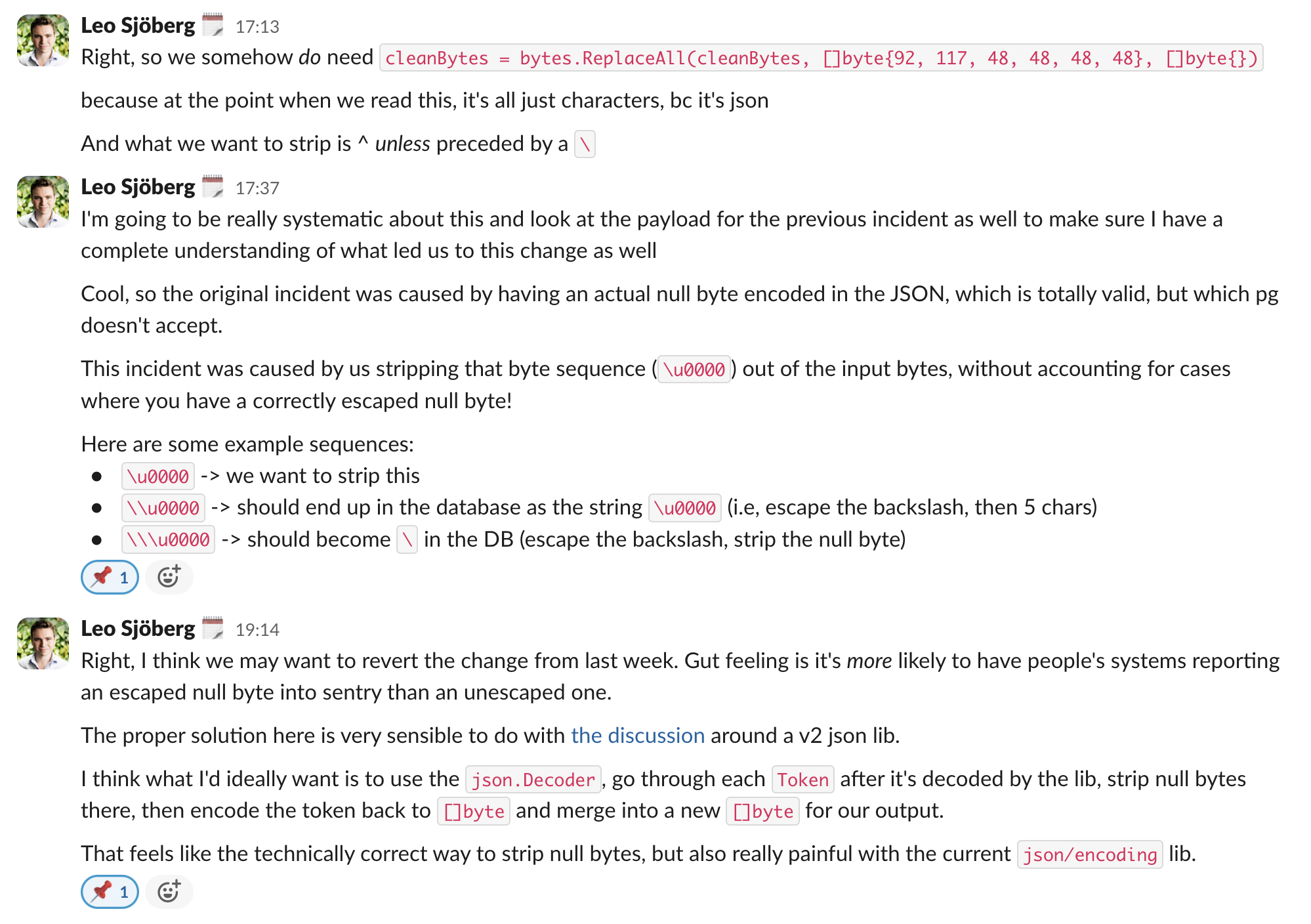
It was at this point I dug down the rabbit hole of encoding.
Pseudocoding what I want
I kept combining research with various experiments in Go as I kept learning, and started writing out what I wanted my code to do:
1func SanitizeJsonBytes(jsonBytes []byte) []byte { 2 dec := json.NewDecoder(bytes.NewReader(jsonBytes)) 3 enc := json.NewEncoder(bytes.NewBuffer([]byte{})) 4 5 for { 6 tok, err := dec.Token() 7 if err == io.EOF { 8 break 9 }10 11 tok = bytes.Trim([]byte(tok.(string)), "\u0000")12 enc.Write(tok)13 }14 15 return enc.Out()16}This would go through the input token-by-token, strip null bytes, and write the token back through an encoder. Now I just had to figure out a way to actually do it. At this point, it was well past working hours, and I decided to pause until the next day...
The problems with encoding/json
As alluded to in my Slack screenshot, decoding and re-encoding a bunch of bytes is painful in
encoding/json, but why? Through my hours of combing through the internet, I happened upon a
GitHub discussion around introducing
a new encoding/json/v2 library, initiated by the fine folks over at Tailscale.
While the aforementioned GitHub discussion goes into much greater depth, in my case it was a very simple
limitation of encoding/json: while there is a Decoder.Token() method to read a JSON payload
token-by-token, there's no Encoder.WriteToken() method to then write that back to an output payload.
The only public method exposed on the Encoder lets you write a complete byte slice ([]byte) of JSON
data.
There was an RFC to introduce WriteToken which was accepted back in 2020, but at the time of writing,
it remains unimplemented.
encoding/json, largely around its inability to handle streams of data which
prevents memory-efficient processing of large JSON data sets, and I highly recommend reading the rationale
for a v2 library by the Tailscale folks, they provide much better nuance than I ever could!
I kept going until way past working hours, and eventually decided to put it down, and continue the next day.
Option 2: Switch from jsonb to json
The next morning, reading up on how Postgres stores and processes JSON data, I announced
I think the easiest solution is to switch from
jsonbtojson
Then followed a quick discussion in Slack, where we realised that, while easy, it's really not ideal. Doing this, you'll end up storing the actual text instead of the decomposed JSON. However, you'll get the same errors at query-time if you do a JSON query, so you're just delaying the problem. Worse yet, you're blind to it until you actually run a query!

Option 3: Store the data in blob storage
We had a quick discussion around whether it would make sense to store the payloads in blob storage. After all, just not storing the data in postgres would solve things! From a technical POV, this may seem like the best option; use the right tool for the right job. However, unless you're already using that tool widely across your stack, you're introducing risk and maintenance cost. How confident are you in your team debugging an error from a database everyone's using every day, vs misconfigured IAM permissions on an S3 or GCS bucket that was configured 9 months ago by someone who's no longer at your company? Unless you're already using the "right tool for the job" widely within your team, introducing it for a minor use case is likely more risk than reward.
Picking an option
On the balance of risk and reward, that last option was the most appealing to us. While it means we don't store a true representation of what was received, we'd never end up rendering it either way, and it allowed us to keep things within postgres, a tool that every engineer at incident.io is familiar with.
It was now late on Tuesday, my second day of this incident. I had learned a lot about JSON, Postgres, and
encoding/json, and felt good about trying out Tailscale's
experimental v2 library (which they themselves
already use in production). But given the time, I decided to relax, and pick up in the morning.
Implementing a fix
Day 3 of this incident. The only words on my mind were escape sequence, json, encoding, UTF-8, and why is the internet so complicated?!
Despite at this point probably having invested somewhere between 10-12 hours just in research and experimentation, I started the day optimistic. I knew what I had to do and how to do it: use Tailscale's experimental JSON encoding library to run through a decoder, sanitise the data, and re-encode, just like my pseudocode.
After only about an hour of work and a bit of debugging, I announced victory
The code
The code for my solution ended up remarkably similar to the pseudocode I wrote two days prior, with a bit more error handling:
1func SanitizeJSONBytes(jsonBytes []byte) ([]byte, error) { 2 dec := jsontext.NewDecoder(bytes.NewReader(jsonBytes)) 3 buf := bytes.NewBuffer([]byte{}) 4 enc := jsontext.NewEncoder(buf) 5 6 for { 7 tok, err := dec.ReadToken() 8 if err == io.EOF { 9 break10 }11 12 if err != nil {13 return nil, err14 }15 16 // Unfortunately, the `jsontext` library doesn't ship these Kinds17 // as variables, but `"` represents a string (you can see this18 // in the `jsontext` source code).19 if tok.Kind() == jsontext.Kind('"') {20 // Strip null bytes from the string21 tokString := string(SanitizeByteArray([]byte(tok.String())))22 tok = jsontext.String(tokString)23 }24 25 err = enc.WriteToken(tok)26 if err != nil {27 return nil, err28 }29 }30 31 // Trim out newlines, which is added by the encoder32 return bytes.Trim(buf.Bytes(), "\n"), nil33}34 35func SanitizeByteArray(byteArray []byte) []byte {36 cleanBytes := bytes.ToValidUTF8(byteArray, []byte{})37 38 // Strip generic null character39 cleanBytes = bytes.ReplaceAll(cleanBytes, []byte{'\u0000'}, []byte{})40 41 return cleanBytes42}This will simply parse the JSON token-by-token, and for any string token, ensure the
input bytes are valid UTF-8, and then strip out the actual null byte. Since we've
decoded the JSON input at this point, we have actual null bytes (i.e the UTF-8 codepoint 0)
in the token, rather than the 6-byte escape sequence, which makes stripping it out much easier.
You may also notice we've updated SanitizeByteArray to no longer strip the escape sequence,
and have switched from bytes.Trim to bytes.ReplaceAll, as we previously accidentally only
removed null bytes from the start and end of tokens (a lesson I learned the hard way by being
paged at 4am).
Where we're at now
In implementing this, I ran into a couple bugs I had introduced and not caught in tests, all of which are now fixed. At this point in time, I feel extremely confident in how we process data coming into our systems from third parties, and hope that it will be many months (years?) before I have to think about sanitising null bytes again.
What I learned
This incident ran across 4 days in the end. While I wasn't working full-time on it, I spent a lot of time learning about working with JSON, Postgres, and Go's encoding libraries.
- One of the biggest realisations might've been that I didn't understand JSON. I thought I understood JSON simply because I work with it everyday, but it couldn't have been further from the truth. I suspect this is the case for a lot of engineers building APIs!
- Encodings are really complicated; every request is a pipeline, and every stage of that pipeline might make different assumptions about character encoding or format.
- Go's
encoding/jsonlibrary leaves a lot to be desired when it comes to low-level processing of JSON streams. Tailscale's library does a really good job of filling these gaps. - Postgres have a really obvious flaw in that it can't store/query completely valid JSON, and this is
accepted as a
wontfixproblem. Unfortunate, and something most users are unlikely to expect, and ultimately what led me down this rabbit hole in the first place!